
Segment Anything:
- Segment Anything segments images into masks regardless of the image type.
- Previous segmentation models were application-specific (e.g., medical, pedestrian detection), but Segment Anything works universally. Earlier methods were pixel wise annotation which is time consuming. Create dataset is expensive, pixel wise annotation very expenssive. not promptable.
Key Features:
- Segments any image without needing to tailor the model to specific types.
- Prompt-based Segmentation: Accepts prompts like points, bounding boxes, or text to direct segmentation, similar to NLP models like BERT or GPT.
Applications and Advantages:
- Can be fine-tuned with prompts for various tasks like medical imaging.
- Reduces the need for extensive dataset-specific training.
Segment Anything
Demo Overview:
- The demo shows how Segment Anything works with different prompts to segment images.
- Users can interact with the model through clicks, boxes, or a combination of both to refine the segmentation.
Interacting with the Model:

Clicks:
- Clicking on a specific part of the image tells the model to focus on that area.
- Users can refine the selection by clicking to remove parts of the segmentation.
Bounding Boxes:
- Users can draw a box around objects to guide the model to segment within that area.
- Further refinement can be done by adding or removing points within the box to include or exclude specific parts.
Real-time Processing:
- The model runs in the browser, showcasing fast, real-time processing without server-side computation.
Innovations Introduced:
Promptable Segmentation Task:
- Works with points, boxes, text, or combinations to segment images based on user input.
Fast Encoder-Decoder Model:
- Generates masks in approximately 50 milliseconds within a web browser.
- Handles ambiguity by returning multiple masks for a given point that may correspond to different objects or parts of objects.
Training Data:
- The model was trained on a massive dataset of 1.1 billion masks.
- Initially trained on a small dataset with manual annotations, it then expanded using semi-automated processes where the model generated masks, which were verified and used to further train the model.
Conclusion:
- Segment Anything is a versatile and efficient model for image segmentation, capable of handling diverse prompts and operating in real-time.
- It leverages a massive, self-improving dataset to achieve high precision, drawing inspiration from advancements in NLP to handle complex segmentation tasks.
Task
NLP and Prompt-Based Models:
- In NLP, models like GPT and BERT predict the next token based on a given prompt.
- Segment Anything adopts a similar approach by using prompts to direct segmentation tasks.
- The model handles ambiguity, returning multiple reasonable masks if a prompt could refer to different objects.

Model Architecture:
- The model is an encoder-decoder architecture.
- Image Encoder: Converts the input image into an embedding.
- Prompt Encoder: Encodes the prompts (points, boxes, text) from the user.
- Mask: An initial mask is created from the first prompt and can be refined with additional prompts.
- Decoder: Uses the image embedding, prompt, and previous mask to predict the final mask and confidence scores.
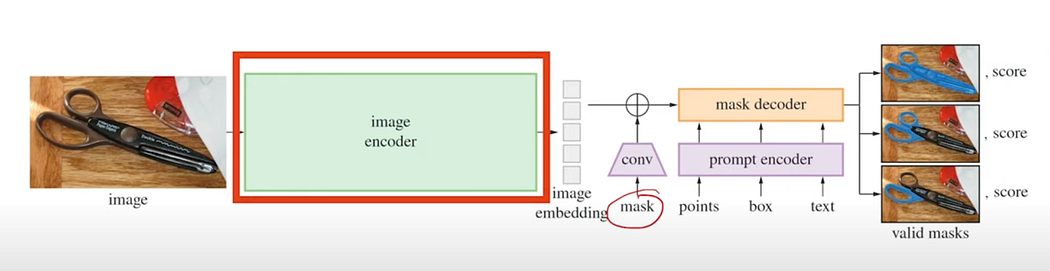
Image Encoder — Vision Transformer:
Key Points:
- The model’s promptable segmentation task allows it to segment images using various types of user input, handling ambiguity by returning multiple masks.
- The encoder-decoder architecture, using a Vision Transformer, processes images and prompts efficiently.
- The model can run in real-time in a browser, showcasing its speed and efficiency.
Training and Dataset:
- The model was trained on a massive dataset of 1.1 billion masks.
- Initially trained on a small dataset, it expanded using semi-automated processes where the model generated masks verified by operators.
- Eventually, the model trained on fully automated mask generation, achieving high precision in segmentation tasks.
Vision Transformer
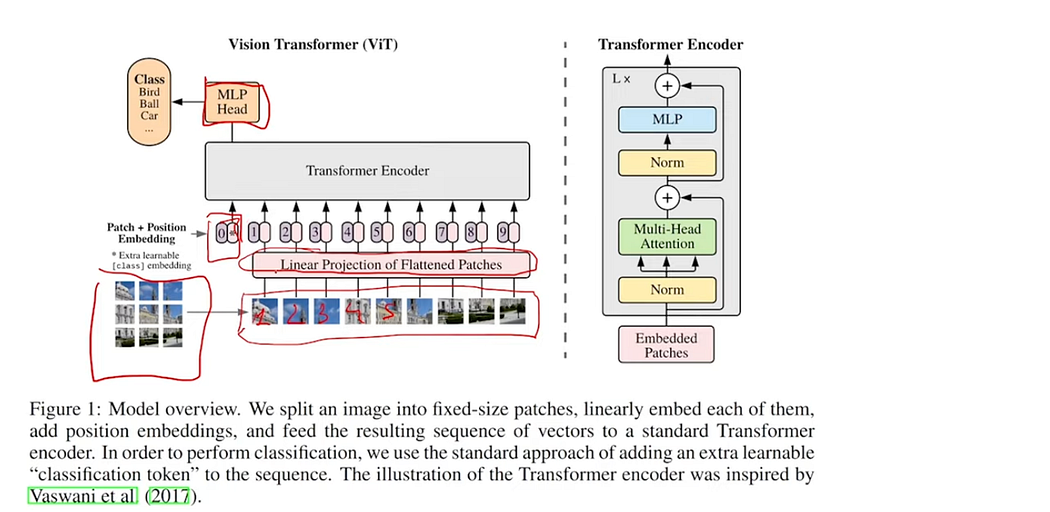
In short:
The “Vision Transformer” paper, titled “An Image is Worth 16x16 Words,” was published by Google Research. The core idea involves dividing an image into 16x16 patches, flattening these patches, and creating embeddings for each patch using linear projection. These patch embeddings, along with positional encodings, are then fed into a Transformer model.
In addition to the patch embeddings, a special token called the “class token” is prepended to the sequence. The class token concept is inspired by the BERT paper. The Transformer model processes the sequence, and through its self-attention mechanism, each token in the output sequence captures interactions with all other tokens.
After processing, the first token in the output sequence, which is the class token, is extracted and passed through a multi-layer perceptron (MLP) to predict the class. The class token, having interacted with all other patches, encapsulates their collective information, enabling the model to make accurate predictions based on the entire image.
Masked Autoencoder Vision Transformer
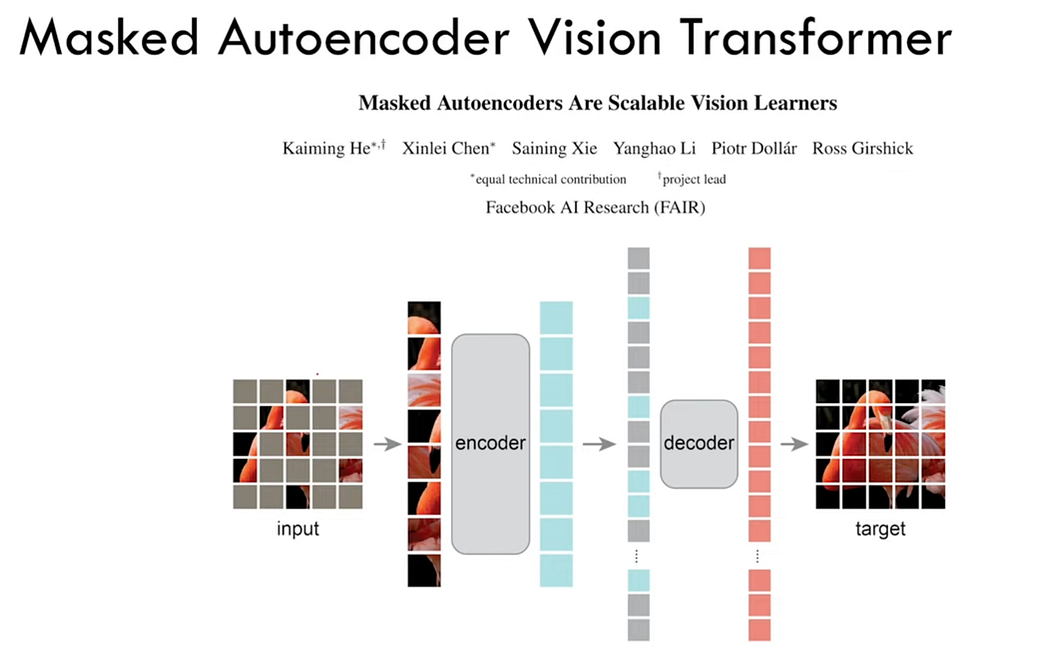
Vision Transformer to Masked Autoencoder:
- The Vision Transformer (ViT) was adapted into a Masked Autoencoder Vision Transformer (MAE) as detailed in the paper “Masked Autoencoders are Scalable Vision Learners” by Meta (formerly Facebook).
- Transformation Process:
- Input Image: The image is split into patches (ref image 1)
- Masking: 75% of the patches are masked (replaced with zeros), leaving only 25% visible.
- Encoding: The visible patches are formed into a sequence and fed into the Transformer encoder, producing an output sequence.
- Reconstruction: The sequence is reconstructed to match the original image structure, with masked patches indicated as empty.
- Decoding: The Transformer decoder attempts to reconstruct the original image from the encoded visible patches and their positional information.
How to reduce the dimensionality of the original image and while preserving the information?
Use
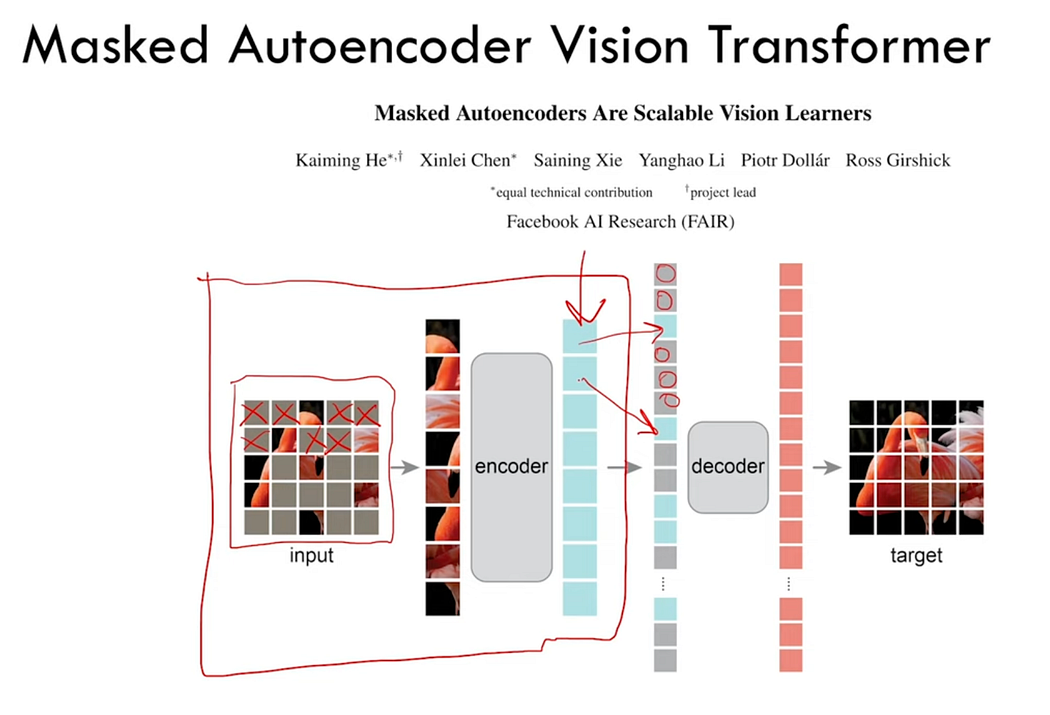
Paper adapted the Vision Transformer into a “Masked Autoencoder Vision Transformer,” detailed in the paper “Masked Autoencoders are Scalable Vision Learners” by Meta (formerly Facebook). In this approach, an input image is divided into patches, with 75% of these patches masked out (in the image the grey areas) and replaced with zeros. The visible patches are arranged into a sequence and fed into the transformer’s encoder, which outputs a sequence.
This output sequence is used to recreate the original image sequence. The positions of the masked patches are retained, while the visible patches are placed back in their original order. The decoder is then tasked with reconstructing the original image using only the embeddings of the visible patches. Despite having access to only 25% of the image, the decoder manages to generate a reasonable approximation of the original image.
The authors of the “Segment Anything” paper incorporated this method because the encoder’s embeddings, which allow the decoder to predict the original image, capture most of the image’s crucial information. This means that the encoder effectively reduces the image’s dimensionality while preserving its salient information, making it highly useful for their purposes.
Model Capabilities:
- The decoder predicts the full image using only 25% visible patches, effectively reconstructing the original image with reasonable quality.
- The encoder’s output captures most of the image’s salient information, essential for high-quality image representation.
Usage in Segment Anything:
- The Segment Anything model uses the MAE Vision Transformer encoder because it efficiently captures the necessary information from the image, reducing dimensionality while preserving key details.
- This embedding serves as a compact, informative representation, enabling the model to generate accurate segmentation masks based on prompts.
Benefits:
- Dimensionality Reduction: The encoder reduces the image to a lower-dimensional space, focusing on important features. This is because 75% of the image is masked.
- Information Preservation: Despite masking most of the image, the encoder retains essential details, making it useful for segmentation tasks.
In summary, the Segment Anything model leverages the MAE Vision Transformer to efficiently encode images, ensuring high-quality segmentation by focusing on the most relevant information within the image.
Scope for Hacking
Briefly,
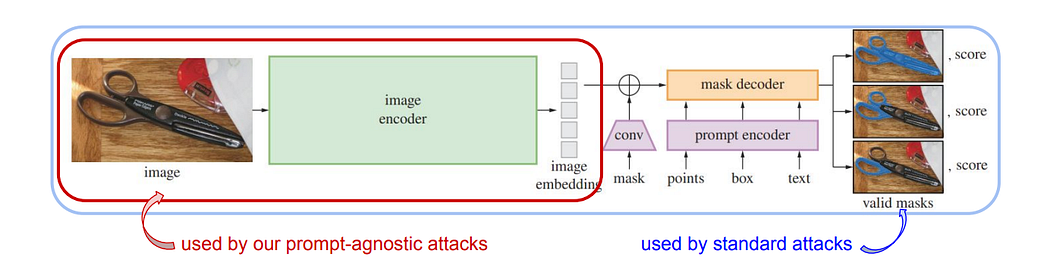
In case of standard attacks, the perturbation is image specific and prompt dependent, so if the prompt is different( box, text etc), the attack becomes ineffective.

Whereas, in the prompt agnostic attacks, the image encoder is perturbed in the latent space.

Result:

Prompt Encoder
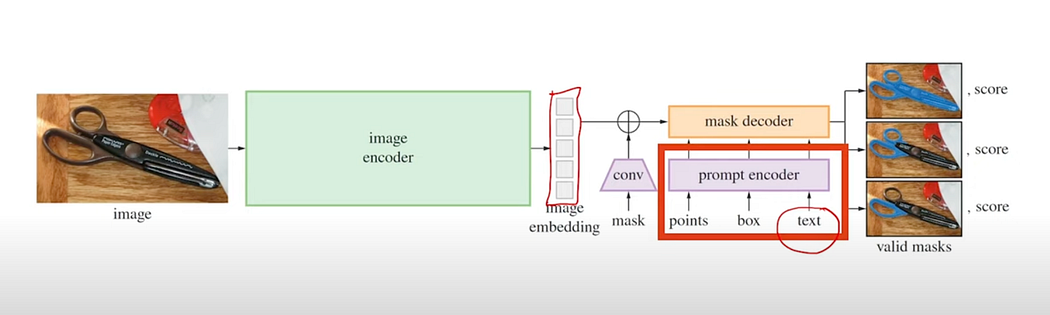
- Role: Encodes user inputs (points, boxes, text) for image segmentation.
- Sparse Prompts: Includes points and boxes.
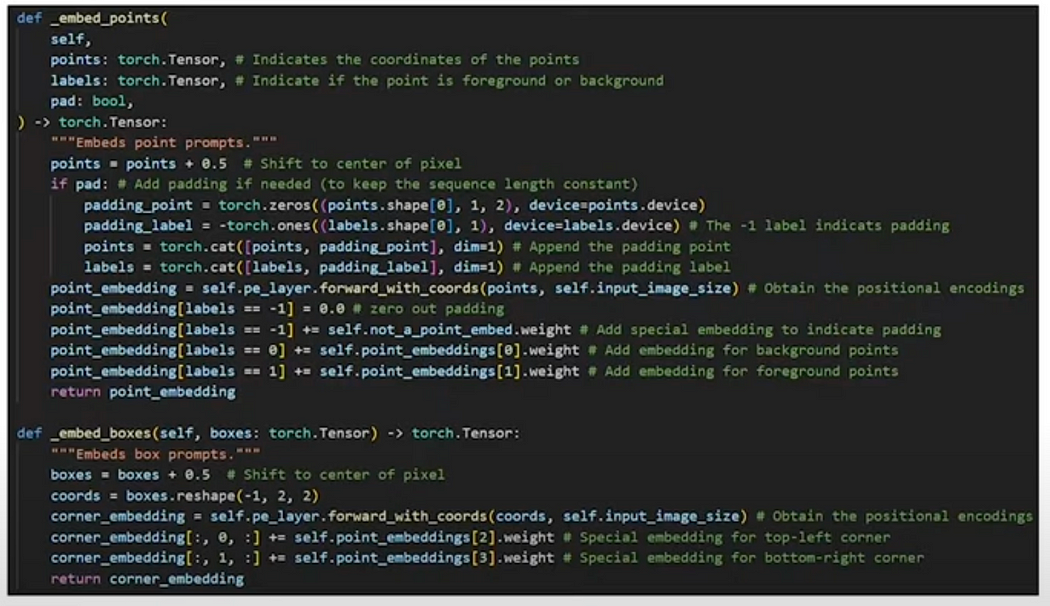
- Points:
- Transformed into 256-dimensional vector embeddings. 256 dim vector to be line with image dimension.
- Points are encoded with positional encodings also.
- Labels (check 1, 0 ,-1 ) indicate whether the point is a foreground (to add) or background (to remove) and -1 for special encoding for padding.
- Boxes:
- Defined by the top-left and bottom-right corners.
- Encoded similarly to points using positional encodings.
- Text: Encoded using the text encoder from the CLIP model.


Dense Prompts:
- Masks: Treated as dense prompts.
- If a mask is specified, it is downscaled through convolutional layers.
- If no mask is specified, a special “no mask” embedding is created.
- Combining Masks and Images:
- The dense mask embeddings are combined with image embeddings via a point-wise sum.

Positional Encodings:
- Purpose: Inform the model of the spatial locations of points within the image.
- Challenges:
- Traditional positional encodings (used in transformers) work for 1D sequences (text) but not for 2D images.
- Solution:
- Developed new positional encodings that handle 2D spatial information.
- These encodings ensure that points at similar Euclidean distances have similar embeddings, providing a meaningful spatial representation.
Learnable Fourier Features:
- Positional encodings need to handle two dimensions (X and Y coordinates).
- Ensure that points close to each other have high similarity, and similarity decreases with distance in a radial manner.
Why New Positional Encodings:
- Required for effective image segmentation to maintain spatial coherence.
- Ensure that the model accurately understands and represents spatial relationships within the image.
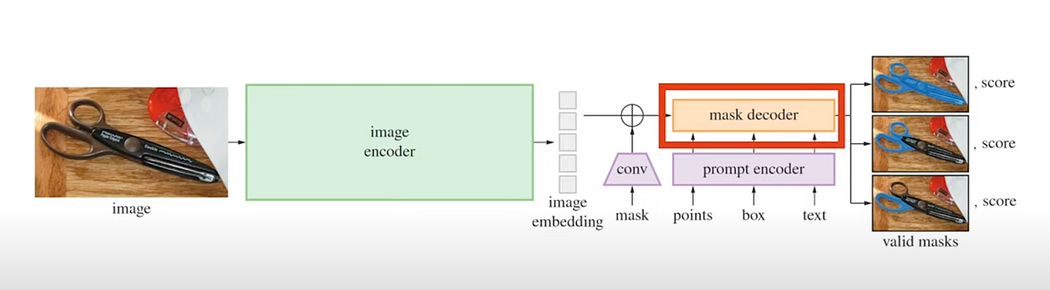
Mask Decoder : most important part
Decoder and the prompt encoder is very fast. How?
Image encoder is need not be very fast as image is encoded only once while loading the image.
Multiple prompts use the same image embeddings over and over again. Prompt embeddings and run to them through the decoder to get the new masks.
mask decoder has to be lightweight and fast and the same goes for the prompt encoder and this is actually the case because that’s why it be could used in browser in a reasonable time.
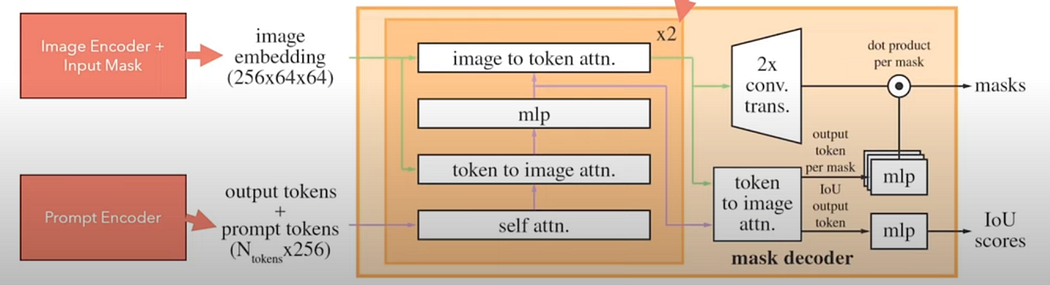
so the mask decoder is made in this way it’s made of two layers so we have to think that there is this block here is repeated again with another block that is after this one where the output of this big block is fed to the other block and the output of that block is actually sent to the model
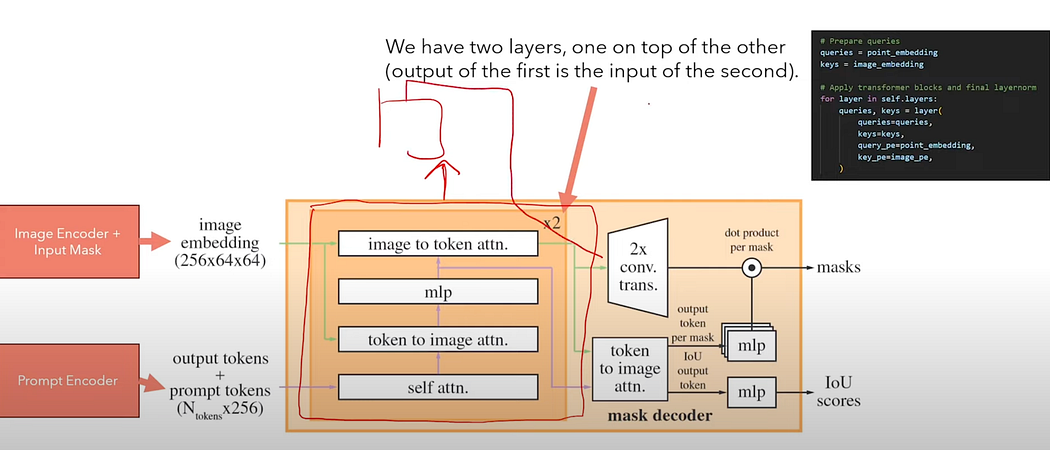
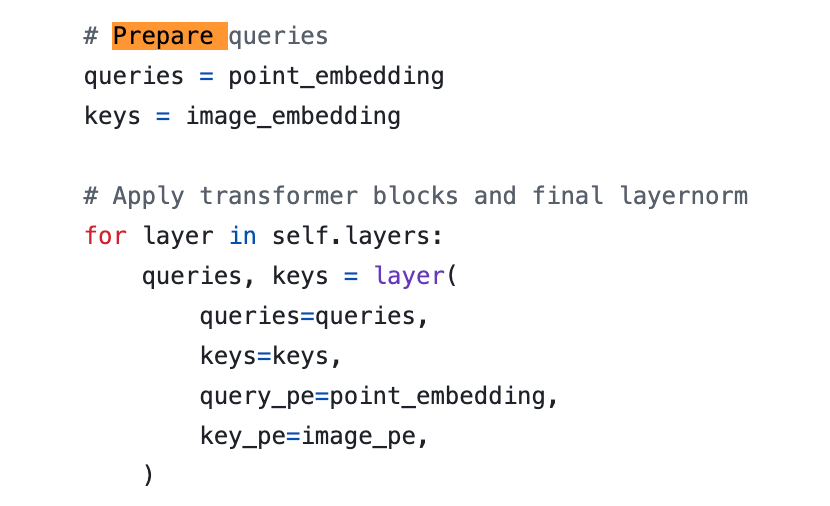
main/segment_anything/modeling/transformer.py
class TwoWayTransformer#forward
Prompt tokens:
The decoder does self-attention between the prompt tokens and the only for the prompt tokens.
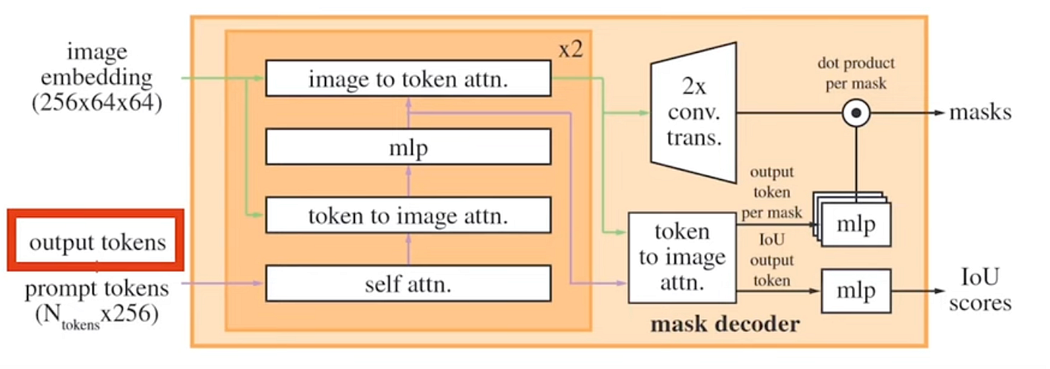
Output tokens:
Output token takes the idea also from BERT model. As explained a little bit in the vision Transformer when image patches were fed to the Transformer encoder they were prepended another token called the class (CLS). The same idea is reused by segment anything (SAM) in which some tokens are appended before the promptable token.

So, the boxes and clicks made by the user are processed by the decoder, which focuses on these tokens and forces the model to encode all relevant information into them. Specifically, there is one token that represents the IOU (Intersection over Union) scores of the predicted masks.
There are three mask tokens, one for each mask. We feed these three tokens, along with one IOU token, into the model. At the output, we extract these tokens: the IOU token is mapped to a multi-layer perceptron to learn the IOU score, while the other three tokens are used to predict the three masks.
The Segment Anything Model (SAM) generates one Intersection over Union (IoU) score and three masks to handle ambiguity and provide flexibility in segmentation tasks.
Ambiguity:
In many image segmentation tasks, a single prompt (such as a click, a box, or a text description) can correspond to multiple plausible segmentations. For example, a click in a crowded scene might refer to different overlapping objects. To address this ambiguity, the SAM model generates multiple mask predictions (3 here).
Multiple mask option:
By generating three masks, SAM offers users multiple segmentation options. This is particularly useful in scenarios where:
- Multiple Objects Overlap: There might be several objects in close proximity, and a single prompt might not clearly indicate which object to segment.
- Different Levels of Detail: Users might be interested in different levels of granularity in the segmentation (e.g., a rough outline versus a detailed contour).
Quality Assurances: IoU
The IoU score is a common metric for evaluating the accuracy of segmentation. It measures the overlap between the predicted mask and the ground truth mask. By providing an IoU score, SAM gives an indication of the quality and confidence of the mask predictions. This is useful for:
- Selecting the Best Mask: Users can use the IoU score to choose the most accurate mask among the multiple predictions.
- Model Evaluation: The IoU score helps in assessing the overall performance of the model.
Steps:
- Prompts : The model takes user prompts (clicks, boxes, etc.) and the image embeddings as inputs.
- Decoder Output: The decoder part of the SAM model processes these inputs and generates a set of output tokens.
- IoU Token: One of these tokens is dedicated to predicting the IoU score. This token encapsulates the model’s confidence in the quality of the segmentation.
- Mask Tokens: The other tokens are used to generate the segmentation masks. SAM produces three masks to cover different possible interpretations of the prompt.
Robustness: The model is more robust to ambiguous prompts, making it more versatile in diverse and complex scenarios.
To clarify let’s take an example:

Imagine a user clicks on a spot that could belong to either a dog or a nearby cat in an image. The SAM model might generate three masks:
- Mask 1: Segments the dog.
- Mask 2: Segments the cat.
- Mask 3: Segments both animals together or a part of the background.
The IoU score helps the user understand which mask is likely the most accurate or relevant to their needs.
In summary, the SAM model creates one IoU score and three masks to effectively handle segmentation ambiguity, provide multiple options to the user, and ensure high flexibility and usability in various scenarios. This approach balances the need for precision with the inherent uncertainty in interpreting user prompts.
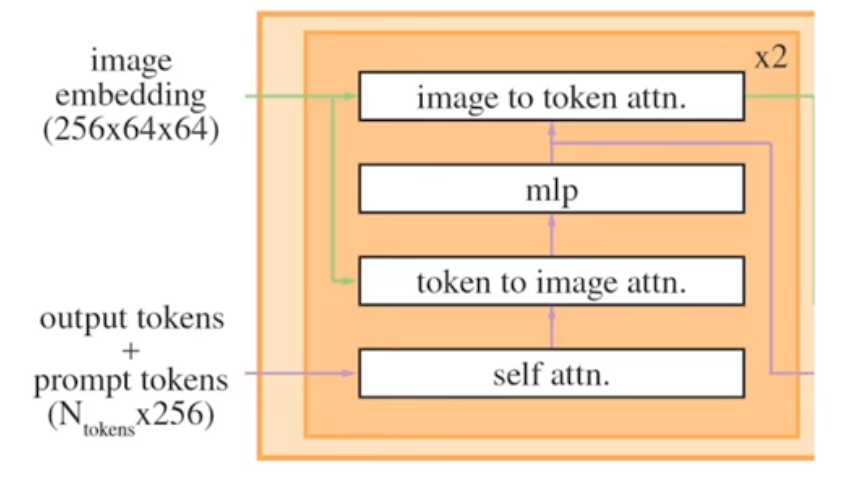

SAM (Segment Anything Model) uses two cross-attention mechanisms in the mask decoder is crucial for effectively integrating information from both the prompt tokens and the image embeddings. Here’s a detailed explanation of why two cross-attentions are needed and how they function:
Integrating Prompt and Image information:
The SAM model generates accurate segmentation masks based on user prompts (such as clicks or boxes) and the image embeddings. Cross-attention mechanisms allow the model to effectively combine these two different types of information:
- First Cross-Attention: This attention mechanism uses the prompt tokens as queries and the image embeddings as keys and values. This step enables the model to align and contextualize the prompt information with the image data, allowing it to understand how the user’s prompt relates to different parts of the image.
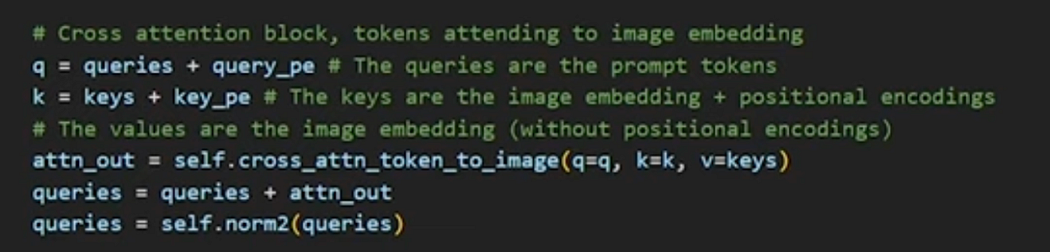
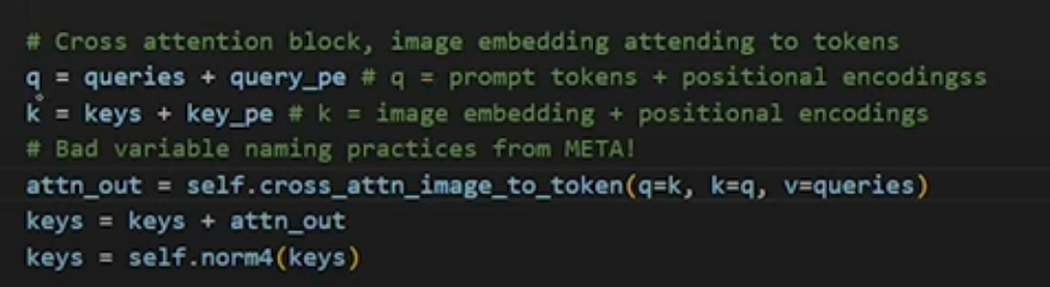
- Second Cross-Attention: This attention mechanism uses the image embeddings as queries and the prompt tokens as keys and values. This step helps refine the image embedding information by incorporating the context provided by the prompt tokens, ensuring that the final embeddings are influenced by both the image content and the user’s intent as expressed through the prompts.
Enhancing the interaction between tokens:
Each cross-attention layer enhances the interaction between the prompt and image tokens in a specific direction:
- First Direction: The first cross-attention layer emphasizes how the prompts relate to the image. By using prompts as queries, it focuses on how user-defined areas or points of interest map onto the image’s feature space.
- Second Direction: The second cross-attention layer, by reversing the roles, ensures that the image features are informed by the prompt context. This bi-directional attention ensures that both the image features and the prompt tokens influence each other fully.
Improving Segmentation Accuracy:
Using two cross-attentions helps the model to better capture complex relationships between the user prompts and the image content. This dual interaction is essential for accurately predicting segmentation masks that are consistent with both the visual information and the user’s input.
How SAM Decoder works:
- Prompt and Image Embeddings Preparation: The prompts (clicks, boxes) and image are encoded into embeddings.
- First Cross-Attention:
- Queries: Prompt tokens.
- Keys/Values: Image embeddings.
- This allows the prompt tokens to gather relevant image information, aligning user inputs with image features.
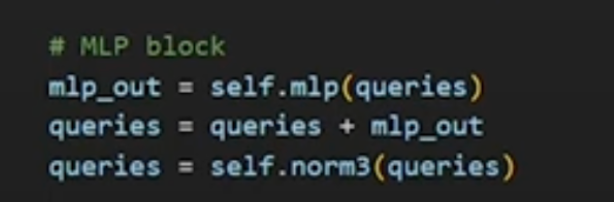
- Intermediate Processing: The output from the first cross-attention layer is processed further (e.g., through a multi-layer perceptron or other transformation).
- Second Cross-Attention:
- Queries: Image embeddings.
- Keys/Values: Prompt tokens.
- This allows the image embeddings to be refined with contextual information derived from the prompts, ensuring the final image features are aligned with the user’s intent.
- Final Output: The refined embeddings are used to generate the final segmentation masks.
Robustness and Flexibility:
The two cross-attention mechanisms make the SAM model robust and flexible in handling various types of prompts and images. By iteratively refining the information from both sources, the model can generate more accurate and contextually appropriate masks.
The dual cross-attention approach in the SAM model is essential for fully integrating and contextualizing both prompt and image information. It ensures that the segmentation process is informed by a comprehensive understanding of both the user’s input and the visual content of the image, leading to more accurate and reliable mask generation.
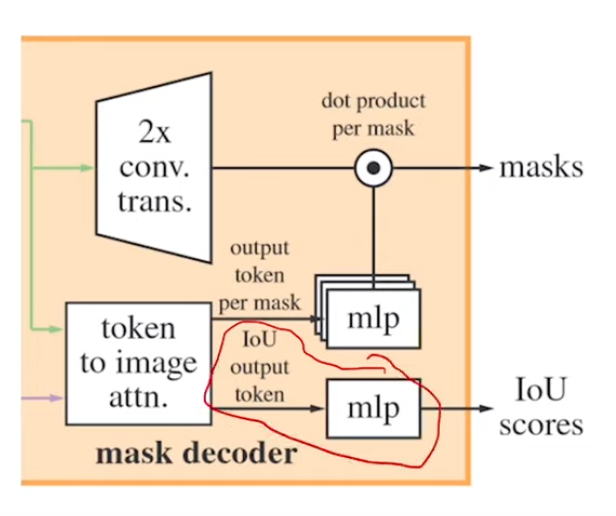
ref: segment_anything/modeling/mask_decoder.py
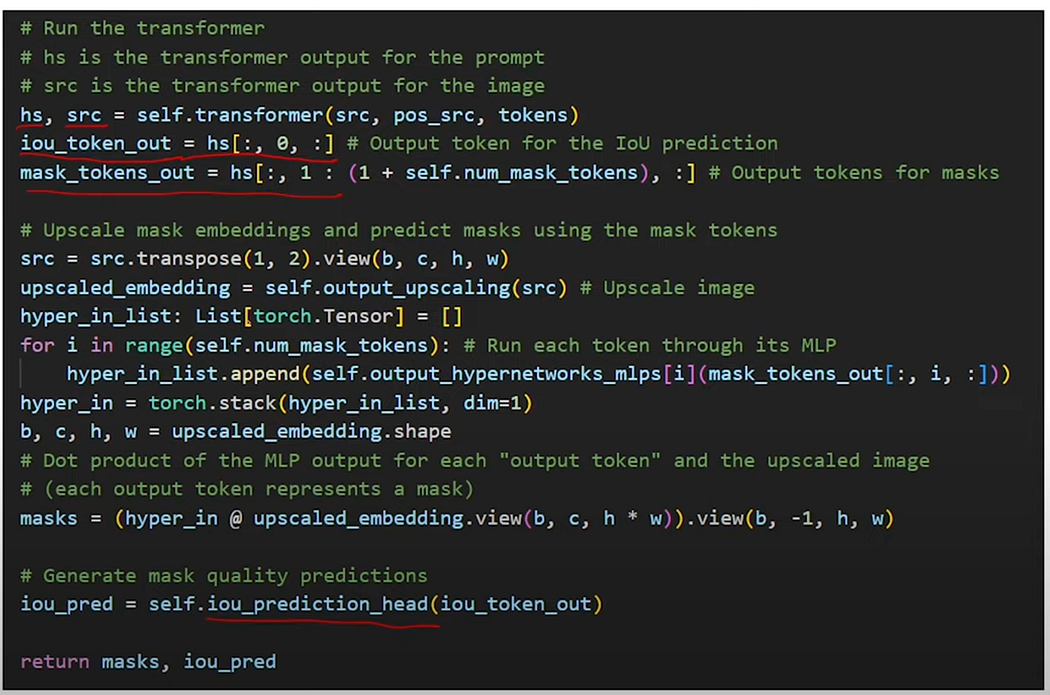


concatenating the iou_token and mask_tokens weights. These tokens learned prompts or starting points for generating outputs related to the IoU score and the segmentation masks, respectively.

Sparse embeddings typically provide a more compact representation where only a few dimensions are active at a time. This can be particularly useful in enhancing the model’s efficiency and focus, allowing it to pay attention to only the most relevant features within the data, which is vital in tasks requiring high precision like segmentation.

This line replicates the image_embeddings tensor along the batch dimension to match the number of tokens being processed. torch.repeat_interleave is used here to duplicate each image embedding a number of times equal to the number of output tokens (including both the IoU token and the mask tokens). This ensures that each token will have a corresponding set of image features to process.
One image embedding per image and multiple tokens per image, this will ensure that each token gets its own copy of the image embedding for subsequent operations.

adding dense_prompt_embeddings to the expanded image_embeddings. It's typical in Transformer models to add some form of embedding or encoded information to the main feature embeddings to enhance the input with additional context or to integrate task-specific features. The dense_prompt_embeddings likely provide such contextual information that aids in better understanding or processing by the Transformer.
Modifies the source embeddings by integrating additional contextual or enhancing information, possibly making the model’s processing of each token more effective in relation to the specific task (like mask prediction).
In the Masked Autoencoder Vision Transformer model, the encoder processes the image patches and the decoder reconstructs the original image from these patches. In the “Segment Anything” paper, the authors adapted this model to encode images into embeddings that capture essential information.
The process involves the following steps:
- Masking and Encoding: The input image is divided into patches, 75% of which are masked out. The visible patches are then fed into the transformer’s encoder, producing embeddings.
- Reconstruction: These embeddings, along with information about the masked patches, are passed to the decoder, which attempts to reconstruct the original image using only the visible patches’ embeddings.
- Prompt and Mask Decoding: The model uses a lightweight, fast decoder to handle user prompts, such as clicks or boxes, and to generate masks in real-time.
The Mask Decoder consists of two layers, each performing several steps:
- Self-Attention: The model runs self-attention on the prompt tokens, which include user inputs and output tokens.
- Cross-Attention: There are two cross-attention layers. The first relates prompt tokens to image embeddings, and the second does the reverse.
- Output Tokens: Special tokens are appended for Intersection over Union (IOU) score prediction and mask prediction. These tokens interact with the image embeddings through self-attention and cross-attention mechanisms.
The decoder produces multiple masks, with three masks predicted for a single prompt and an additional mask when multiple prompts are provided. This design helps manage ambiguity in the segmentation tasks.
The model’s effectiveness relies on the powerful yet slow image encoder, which is run only once per image. The lightweight, fast mask decoder and prompt encoder ensure quick response times for real-time interactions, such as those demonstrated in a web browser application.
Summary of Decoder:
The mask decoder handles prompts and generate corresponding masks efficiently:
- Inputs to the Decoder: The decoder receives prompts (clicks or boxes) and the image embedding. The image embedding is combined with the mask through element-wise addition.
- Self-Attention on Prompts: The decoder first applies self-attention to the prompt tokens, including special output tokens.
- Output Tokens: These tokens include one for IOU prediction and three for mask predictions. They are designed to capture the necessary information to produce masks and IOU scores.
- Cross-Attention Layers: The first cross-attention layer uses prompt tokens as queries and image embeddings as keys and values. The second cross-attention layer reverses this, using image embeddings as queries and prompt tokens as keys and values.
- Maintaining Positional Information: Positional encodings are added to both image embeddings and prompt tokens at each attention layer to preserve geometric information.
- Producing Masks: The output tokens for masks are combined with the upscaled image embeddings. Each mask token is processed through its own MLP (multi-layer perceptron) to generate the final mask.
Ambiguity:
Paper introduce a mechanism to predict multiple masks:
- Single Prompt: For a single prompt, the model predicts three masks to account for potential ambiguities.
- Multiple Prompts: When multiple prompts are given, a fourth token is used to predict an additional mask, which helps refine the segmentation based on additional information provided by the user.
This approach ensures that the model can handle ambiguous inputs and produce accurate segmentations across a variety of scenarios.
- Responsiveness: The decoder in the Segment Anything model is designed to be lightweight and fast, allowing for real-time updates when users add points or make selections in the browser.
- Prompt and Image Embeddings: The image is encoded once and stored. Multiple prompts can be encoded quickly and combined with the image embeddings to generate segmentation masks.
Structure:
- Layer Structure: The decoder consists of two main blocks, where the output of the first block is fed into the second block. The output of the second block is then used to produce the final segmentation masks.
- Inputs: The decoder takes the prompt tokens (user clicks, boxes) and the image embeddings (combined with mask embeddings) as inputs.
Attention Mechanisms:
- Self-Attention: Applied to the prompt tokens to capture relationships within the prompt.
- Cross-Attention: Two stages of cross-attention are used:
- First Cross-Attention: Queries from prompt tokens, keys, and values from image embeddings.
- Second Cross-Attention: Queries from image embeddings, keys, and values from prompt tokens.
Output Tokens:
- Purpose: Output tokens are added to the prompt tokens and include special tokens for Intersection Over Union (IOU) and mask predictions.
- IOU Token: Predicts the IOU score of the masks.
- Mask Tokens: Predicts the segmentation masks.
- Process: The output tokens interact with the prompt tokens and image embeddings through self-attention and cross-attention layers.
Positional Encodings:
- Purpose: Ensures that spatial information is retained throughout the decoding process.
- Implementation: Positional encodings are added back to the image embeddings and prompt tokens at every layer to maintain geometric information.
Output Generation:
- Upscaling: The image embeddings are upscaled.
- MLP Layers: Each mask token is processed through its own multi-layer perceptron (MLP).
- Combination: The outputs from the MLPs are combined with the upscaled image embeddings to produce the final segmentation masks.
Ambiguity Handling:
- Multiple Masks: The model predicts multiple masks (usually three) to account for possible ambiguities in the prompt.
- Additional Token: An extra token is used to predict an additional mask when multiple prompts are provided.
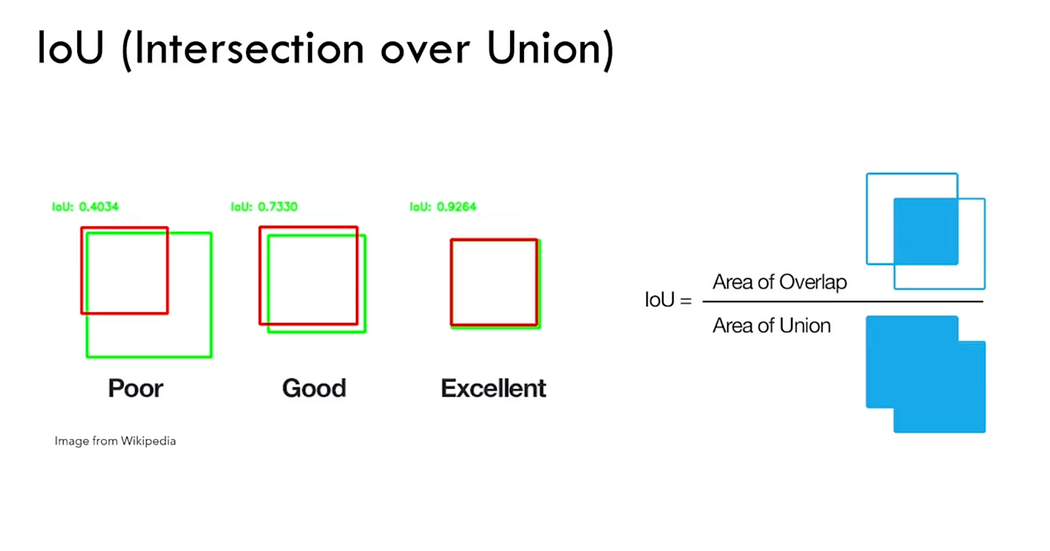
Intersection Over Union (IOU):
- Definition: IOU measures the overlap between the predicted mask and the ground truth mask.
- Calculation:
- False Positives: Areas predicted but not in the ground truth.
- False Negatives: Areas in the ground truth but not predicted.
- Perfect Match: Achieved when the predicted mask exactly matches the ground truth, maximizing the intersection and minimizing the union area differences.
Key Concepts:
- Efficiency: Decoder is optimized for speed, allowing real-time interaction.
- Attention Mechanisms: Crucial for capturing relationships between prompts and image embeddings.
- Positional Encodings: Vital for maintaining spatial coherence.
- Ambiguity Awareness: Predicts multiple masks to handle uncertainties in prompts.
- IOU Metric: Used to evaluate the accuracy of the predicted masks against ground truth.
This detailed process ensures that the Segment Anything model can generate accurate and efficient segmentation masks in real-time, leveraging sophisticated encoding and decoding strategies along with robust attention mechanisms.
Loss Function
Model Loss:
- Combination of Losses: The model’s loss function is a combination of focal loss and dice loss, used in a ratio of 20:1.
- Focal Loss:
- Origin: Derived from cross-entropy loss.
- Purpose: Addresses class imbalance, where most pixels are non-mask and only a small percentage are mask pixels.
- Application: Adjusted cross-entropy for dense object detection, introduced by Facebook Research.

- Dice Loss:
- Origin: Based on the Sørensen–Dice coefficient, also known as the F1 score.
- Calculation: Twice the intersection area divided by the total area (similarity measure). Loss is computed as 1 minus the dice score.
- Use Case: Commonly used for segmentation tasks, introduced in the V-Net paper (2015).
Data Engine and Dataset Creation:
- Scale: Segment Anything was trained on 1.1 billion masks from millions of images.
- Three-Stage Data Engine:
- Manual Stage:
- Process: Professional annotators manually labeled images using brush and eraser tools, creating pixel-accurate masks from scratch.
- Semi-Automatic Stage:
- Process: The model, trained on manually created masks, generated initial masks. Annotators then refined these masks and added any missing objects.
- Fully Automatic Stage:
- Process: The model generated masks without human intervention.
- Mechanism: The model created a 32x32 grid of points on each image and predicted masks for each point, selecting the mask with the highest confidence and stability (thresholded probability map at 0.5 ± Δ).
- Post-Processing: Non-Maximal Suppression (NMS) was used to remove duplicate or overlapping masks.

Non-Maximal Suppression (NMS):
- Purpose: Used to eliminate redundant masks, ensuring only the most confident and distinct masks are retained.
- Application: Commonly employed in object detection tasks to filter out overlapping predictions.
This summary encapsulates how the Segment Anything model combines different loss functions to handle class imbalances and uses a sophisticated data engine to create an extensive dataset for training. The data engine progresses from manual annotation to semi-automatic refinement, and finally, to fully automatic mask generation, ensuring high-quality and diverse training data.
Non Maximal Suppression
In object detection, multiple bounding boxes often overlap for the same object. To select the best one, the following process is used:
- Select Highest Confidence Box: Choose the bounding box with the highest confidence score.
- Eliminate Overlapping Boxes: Remove all other bounding boxes that have an Intersection Over Union (IOU) with the selected box above a certain threshold.
- Repeat for Remaining Boxes: Apply the same process to the remaining boxes.
This algorithm effectively reduces redundancy by keeping only the most accurate bounding box for each object.
Conclusion and Invitation: The presenter thanks viewers for watching the video on the Segment Anything model, invites comments for clarification, and encourages subscribing to the channel for more future content.
ref: https://arxiv.org/pdf/2311.14450




