
Computer vision systems aim to simulate the human visual system, allowing machines to understand or infer objects based on visual information from digital images or videos.
The process involves the machine interpreting the visual information obtained by cameras, like the human brain processes visual information from the eyes to recognize objects like cats.

Understanding 3D data is a key aspect of 3D computer vision, a specialized branch of computer vision that directly utilizes 3D data from various sensors like Lidar, depth camera, unlike traditional computer vision that interprets 2D images derived from 3D space.
Methods to obtain 3D data include:
- Stereo images for stereo depth
- Multi-view geometry from multiple images
- Real-time acquisition using RGB-D cameras or LiDAR
Processing this 3D data involves comprehending the environment and extracting necessary information, similar to tasks in conventional computer vision.
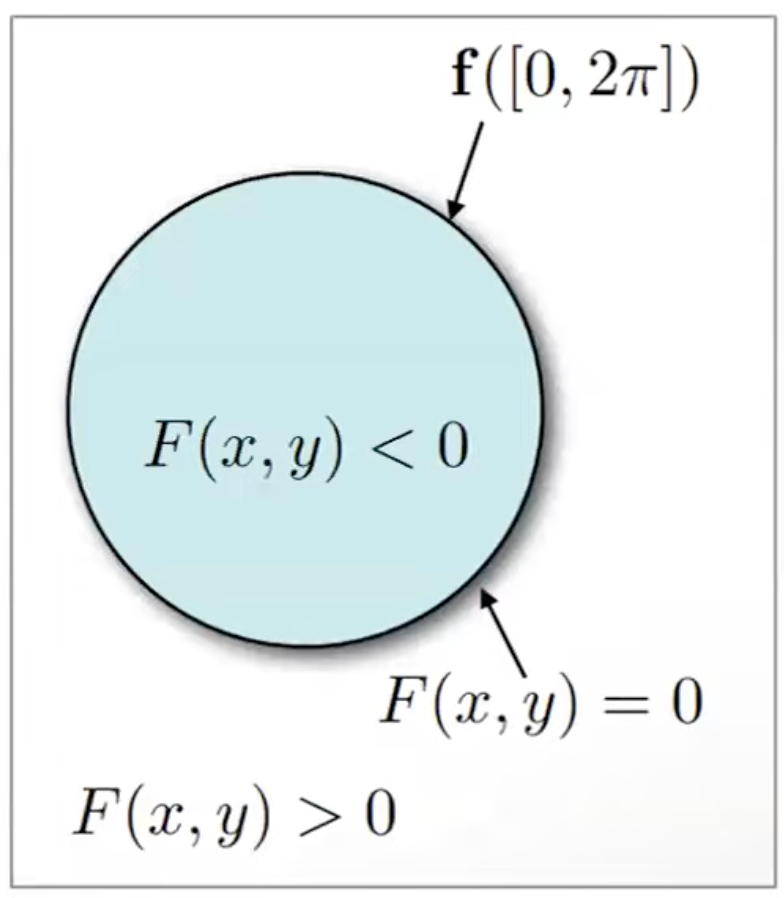
3D surfaces can be represented in two main ways:
a) Parametric (explicit) surfaces
b) Implicit surfaces

a) Explicit surfaces, or parametric surfaces, directly represent surface shapes by specifying details like position, distance, or normal vectors. **Point clouds, a type of explicit surface, will be our primary focus.
b) Implicit surfaces represent 3D shapes mathematically, using a function’s threshold value to define the surface. This approach allows for handling more complex shapes than explicit surfaces. For example, an explicit method directly specifies a circle’s curve, while an implicit method mathematically defines the circle, indicating whether a point is inside or outside based on the function’s value.
Signed distance functions (SDFs) are a common implicit surface representation, useful for evaluating topology by determining if a point lies inside or outside a volume.
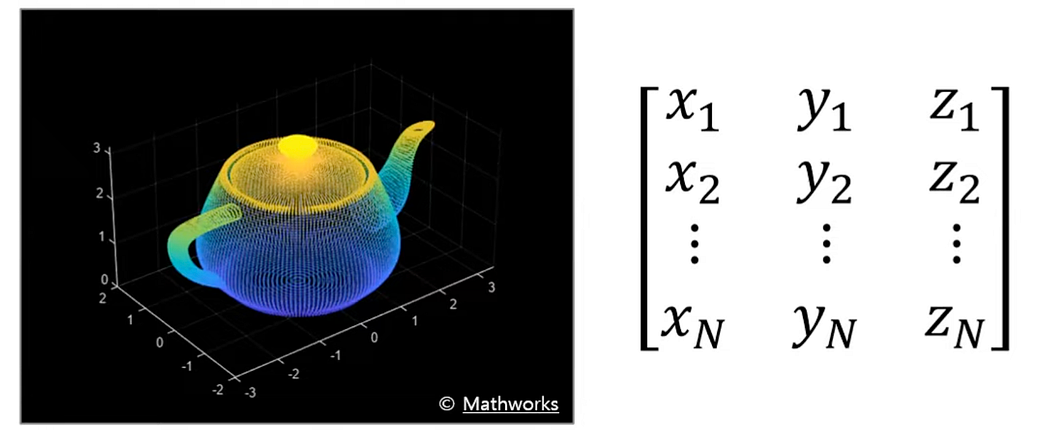
Point clouds explicitly represent 3D positions and normal vectors in space. They are mathematically simple, typically expressed as arrays of 3D vectors, and can range from a few dozen to millions of points. An example is a teapot object represented as a point cloud with positions specified along the X, Y, and Z axes.
Point clouds can include additional information such as color from an RGB-D camera, forming a 6D vector (X, Y, Z, R, G, B). They may also include surface normal vectors, resulting in another form of 6D vector (X, Y, Z, Nx, Ny, Nz), along with other geometric features or embeddings.
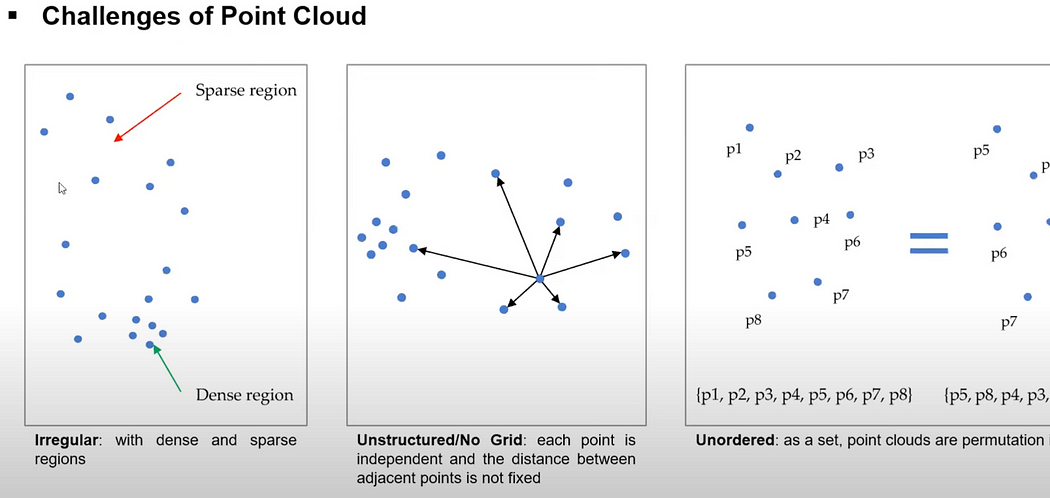
Unlike the structured format of 2D images, point clouds are unstructured with no inherent order, which complicates the processing of 3D data. Various methods are required to handle this unstructured nature, which will be explained further.
Comparing 2D images with point clouds: 2D images represent 3D information projected onto a 2D plane and are structured in a 2D space with defined resolutions like 1024x768. In contrast, point clouds maintain the 3D data structure directly but lack inherent order, structure, or contextual information about surrounding points. This lack of structure and context makes it challenging to infer and utilize 3D information from point clouds.
Point clouds, obtained from sources like LiDAR, depth cameras, or multi-view geometry, have varying densities. Some areas are densely packed with points, while others are sparse or contain noise and outliers. This irregular nature requires careful handling during processing. For instance, depth cameras and LiDAR capture dense data at close range but produce sparser data as distance increases. Similarly, stereo matching or structure-from-motion results in denser point clouds in areas with many features and sparser regions in areas with poorly matched features.
Point clouds also lack uniform or fixed distances between points. Techniques like neighboring search are needed to understand surrounding information. Additionally, point clouds lack order; two point clouds with the same shape and distribution can have different data orders, affecting data communication and processing.
Handling point clouds effectively requires algorithms that are robust to changes in data order. Due to these characteristics, deep learning methods have recently shown promising performance in 3D computer vision tasks. While 2D images benefit from convolutional neural networks (CNNs) due to their structured format, similar approaches are being adapted to manage the unstructured nature of point clouds.
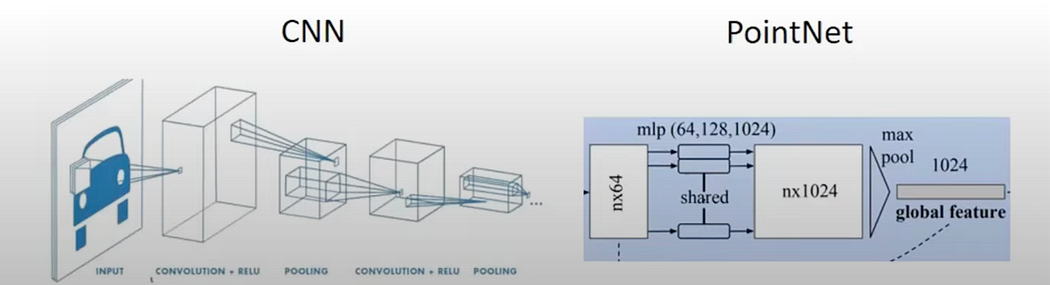
Deep learning techniques have become mature and perform well in computer vision. However, directly applying convolution operations to 3D point clouds is challenging due to their irregular and unstructured nature. Therefore, specialized network designs are required to handle point clouds effectively, unlike the general CNN structures used in traditional computer vision.
special. handling required:
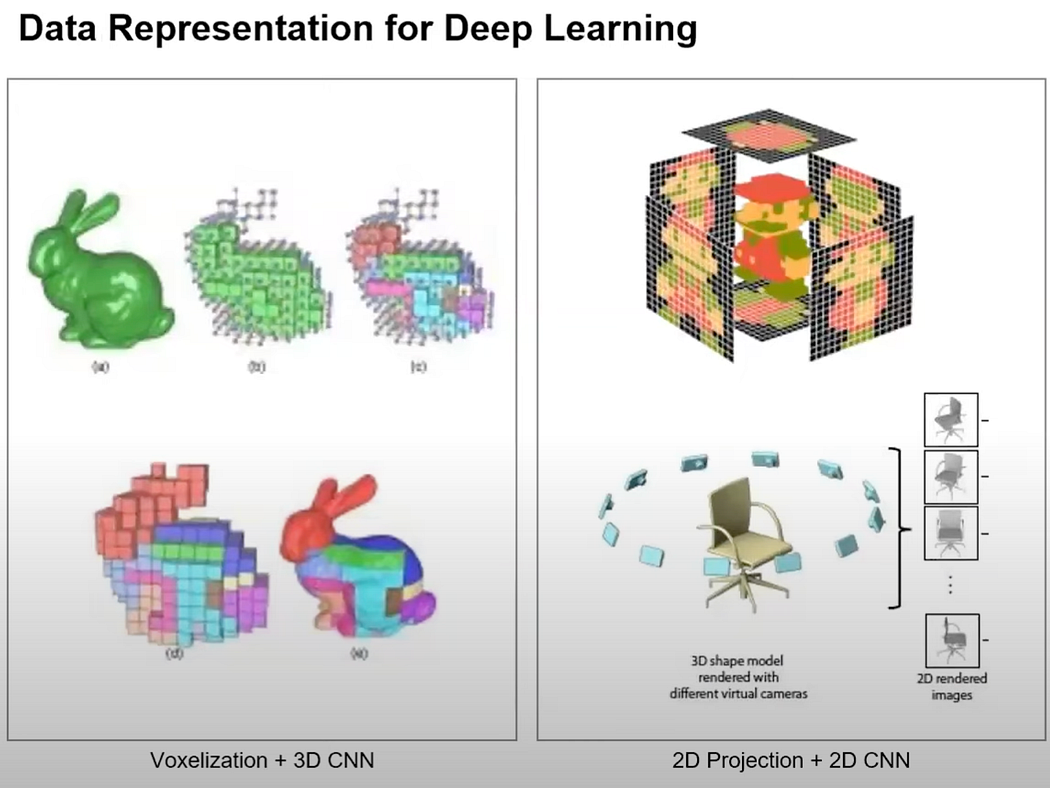
Several approaches have been developed to manage 3D data, such as structuring it into voxels for 3D convolutions, projecting it onto 2D planes, or designing neural networks specifically for point clouds. These techniques have been extensively researched.
RGB-D data, like that from the Microsoft Kinect, includes depth information along with RGB channels. Using the camera’s intrinsic parameters, depth information can be represented as a point cloud. This data can leverage 2D convolution and deep learning techniques used in traditional computer vision.
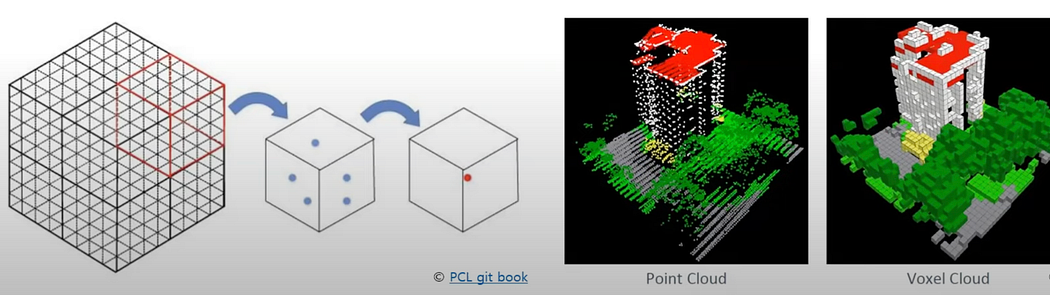
3D data can also be represented using structures like voxels or octree grids, which apply structured entities from 2D to 3D. Voxel representation makes it easier to apply convolution operations, but it requires significant computation time and memory, especially for high-resolution data.
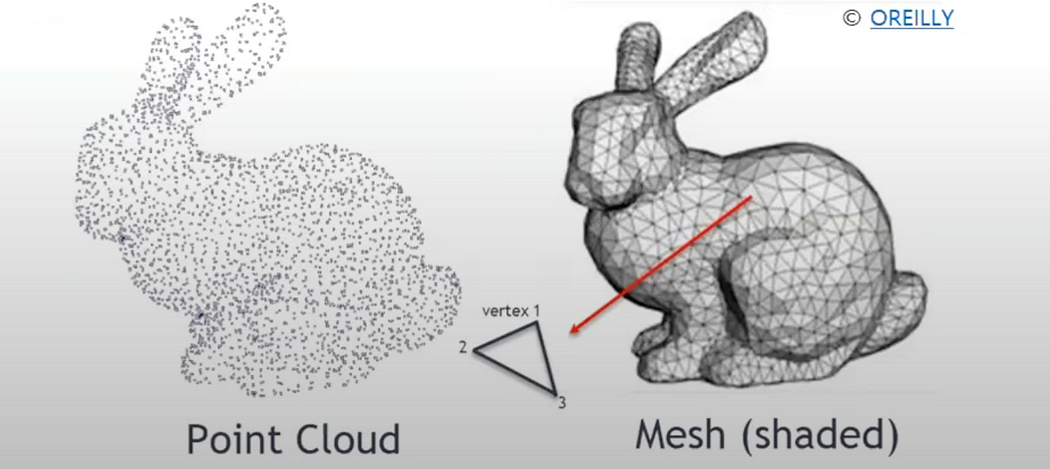
Another format is the mesh model, common in graphics. Unlike point clouds, meshes provide connectivity information between points, making it easier to represent continuous surfaces and perform tasks like rendering. However, converting point clouds to meshes requires an additional meshing or triangulation process, which is not always optimal.
Point clouds, being raw sensor data, are often directly handled in real-time applications. Processing point clouds involves various techniques, mathematical models, and algorithms. Traditional methods have predominantly used mathematical models, but deep learning approaches have recently shown great performance.
Specialized deep learning models are needed to handle unstructured, unordered data effectively. Traditional point cloud processing methods, such as registration, align two point clouds by finding a transformation matrix, usually limited to rigid transformations in practical applications.

Point Cloud Processing Techniques:
Registration: This method finds the optimal rotation and translation to align point cloud A with point cloud B. It connects features from different parts of a 3D object to create a watertight 3D point cloud, forming a complete object. Registration is also used in creating maps from scanned real-world environments using sensors like RGB-D or LiDAR. Registration techniques using point cloud alignment.
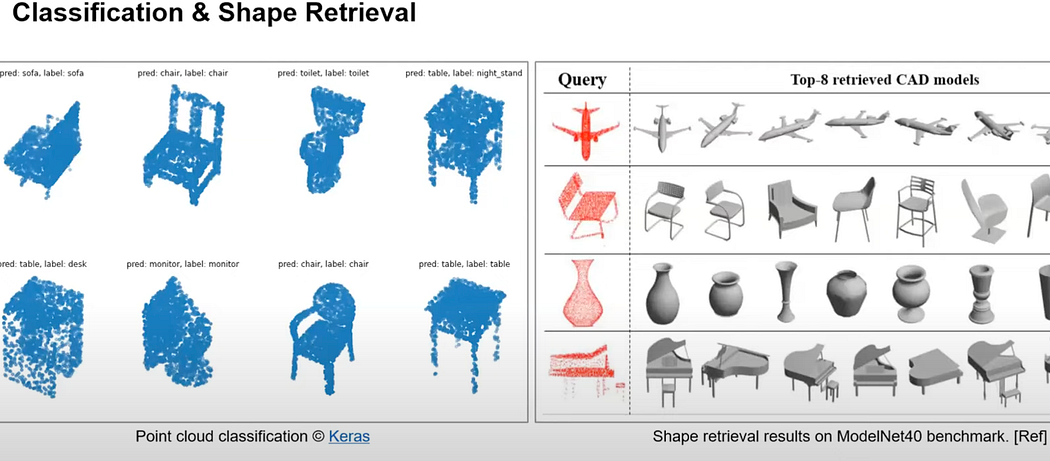
Classification: Similar to 2D image classification, this process categorizes point clouds into predefined classes. Traditionally, geometric features were extracted from 3D point clouds and classified using traditional machine learning techniques. Recently, deep learning methods have been developed for end-to-end feature extraction and classification, categorizing objects like chairs, tables, and monitors.
Shape Retrieval: This task involves searching a database for objects with similar shapes or the same class as a given point cloud. Semantic segmentation assigns classes to each point in the point cloud, enhancing understanding and enabling object detection, which infers the location and size of objects in 3D space.
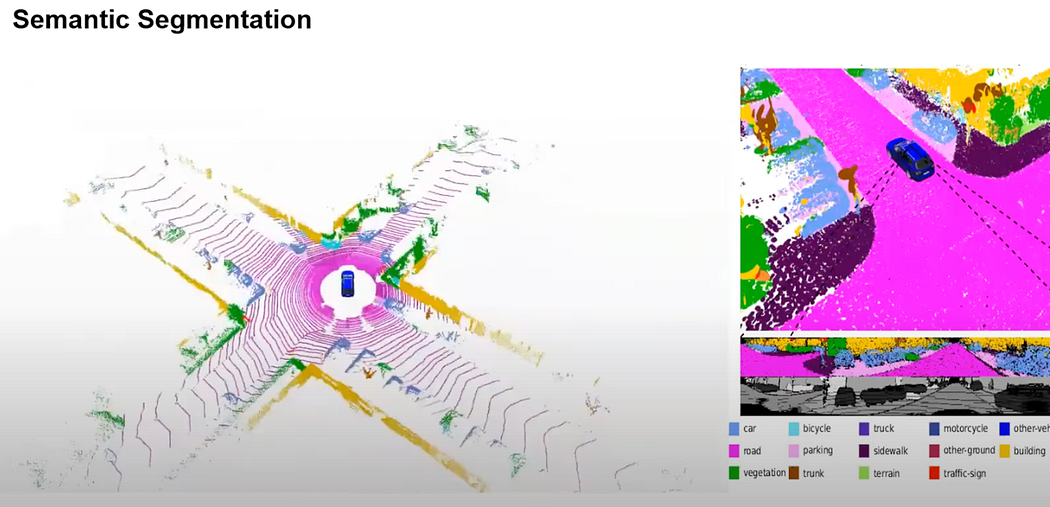

Object Detection: A sub-task of segmentation, it detects the position, size, and type of objects in 3D space. This method is used in applications like autonomous driving and augmented reality. The Kitti dataset, for example, labels each point with categories such as road, car, and pedestrian.
Odometry: This method estimates location along a path using sensors like GPS and IMU, with recent developments in visual and LiDAR odometry inferring motion from continuous frames of point cloud data. Odometry is crucial for Simultaneous Localization and Mapping (SLAM), with examples like LeGO-LOAM using 360-degree LiDAR to map environments. Odometry involves feature extraction, registration, and alignment tasks.
Various datasets and algorithms have been developed for point cloud processing, including CAD models used to create labeled point clouds for tasks like object classification and shape retrieval.
ref: cs231N stanford.edu




